

観察学習における強化
オペラント条件付けにおける学習は、模倣された行動の結果に対し生じる好子(褒美)によって強化されると言います。
図式化すると以下のようになります。
モデル刺激→反応→強化刺激→[反応へ還る]
それに対し、学習と遂行を分割する社会的学習理論において、学習そのものは外的強化なしに生じます。
しかし、何を認知し注意するかという観察の方向性や、何をコード化したり統合したりするかという保持の選別は、「強化の予期」によって決定されます。
観察されたあるモデルの行動が報酬や罰の回避をもたらすことが分かると、その方向に観察の注意が向き、記憶や統合においても有益で価値の高いそれらの反応が選択の基準となります。
図式化すると以下のようになります。
予期的強化刺激→注意→モデル刺激→保持(コード化、体制化、リハーサル)→反応
オペラント条件付けにおいて強化は必要条件ですが、社会的学習理論においてはひとつの促進条件でしかありません。
注意の要因は強化以外にもあるからです。
人は単に利害関心のみによって対象を志向する訳ではありません。
対象の特徴が外的に際立っていたり、観察者の内的特性が注意の幅を限定していたり、利害関心による注意に付帯的な隣接した行動が偶然学ばれたり、注意には様々な要因が存在しているからです。
例えば、暗い部屋のテレビに映る行動は、別に子供たちに学習の動機付けを与えずとも、自然に模倣学習されてしまいます。
直接強化、代理強化、自己強化
オペラント条件付けは主体に対する直接的な外的強化による「直接強化」のみを考えますが、社会的学習理論はそれに加え、間接的な「代理強化」と内的な「自己強化」によって行動が制御されると考えます。
もちろん、それらは個々別々に働くのではなく、相互作用的、複合的に働くことになります。
例えば、観察された結果(代理強化)の報酬より、自分に与えられた結果(直接強化)の方が少ないなら、私へのその報酬はむしろ罰として機能してしまいます。
他の子は勉強すれば飴玉を10個貰えるのに、自分だけ1個しか貰えないなら、それは行動を強化せず弱化させます。
また、人間は結果を予期したり、反省的に自分の行動を評価したりしながら、自ら行動を制御するという高次の心理的機能を持っています。
行為の基準を自ら設定し、自らが自らに要求を課し、その結果によって自らに報酬を与えたり自罰を与える、強化の自己管理システムを持っているのです。
当然、外的結果と内的結果は合致せず葛藤が生じることも多々あります。
例えば、試合で優勝して、皆に賞賛されているにもかかわらず、自分の不甲斐なさに怒り、笑顔を見せない選手がよくいます。
彼は自己管理システムが非常に発達しているので、自分が課した自分への要求(レコードなり勝ち方なり)が達成できなかった以上、いかに優勝という最高の外的結果を得ても、何の満足も与えないのです。
逆に孤独な革命家のように、周囲の承認や賞賛が得られなくても、自己管理システムによって、自分の道を黙々と歩み続け、偉業を達成する者もいます。
代理強化の六つのメカニズム
1.情報機能~他者の行為の結果いかん(報酬-罰、承認-否認など)によって、ある行動の価値が観察者に与えられます。
この情報を基にした予期によって観察者は模倣行動を制御します。
2.環境の弁別機能~同じ行動でも状況が異なれば、異なる結果を生じさせます。
他者の観察は、行動の価値と同時に、この状況(コンテクスト)を読む能力を発達させます。
同じ模倣行動でも、状況に応じて、行ったり慎んだりすることが可能となります。
3.誘因、動機付け機能~他者の強化を観ることで、その行動は動機付け、価値付けられます。
それへの期待により、遂行の頻度、速度、強度、持続性などが決定されます。
4.代理的情動覚醒機能~他者の行為の結果と、その結果に接した時の他者の情動反応は、観察によって紐付け(条件付け)られます。
他者の情動の観察は、感情移入的に観察者の情動を喚起、覚醒させ、その紐付けは代理的に働き、自己自身の内でもそれが採用されるようになります。
例えば、赤点を取ったクラスメートが先生にひどく怒られ、恐怖に怯えるのを見ると、観察者も赤点を取った時、恐怖反応が生じます。
逆に、赤点を取っていつも親や先生に怒られることに怯えていた観察者が、赤点を取って先生に怒られても平気な顔をして笑っているクラスメートを見ると、自分も恐怖反応が消去され平気になっていきます。
5.モデルの地位付け機能~1.の情報機能が行動の価値に向けられていたのに対し、これはモデルとなる行為者に向けられます。
褒美や賞賛を受ける行為をたくさんする人は、観察者の中で地位の高い人として、見習うべき人となります。
このモデルの格付けが、観察者の模倣の度合いに影響を与えます。
6.強化操作者の価値付け機能~モデルとなる人だけでなく、モデルに強化(褒美や罰)を与える人間(強化操作者)の価値付けも観察によって行われています。
強化操作者がモデルに対し公正に褒美や罰を与えているなら、観察者の中で強化操作者としての評価は高くなり、その強化の影響も大きくなります。
しかし、それが権力の乱用のような不適切なものである場合、むしろその強化は逆の方向へ作用します。
例えば、決められたことをきちんと守る優等生が、同級生が理不尽に処罰されたことに憤慨し、違反行動を増大させる時、それは教師に対する信頼を失い、観察者の中で教師の強化操作者としての価値が失われるからです。
これらのメカニズムの複合によって、代理強化の模倣傾向は変化します。
以上述べてきた理論を実験によって実証した代表的なものが、有名な「ボボ人形実験」です。
以下、その概要です。
ボボ人形実験その1(1961)
1961年、36人の男児、36人の女児、計72名の被験者を対象に行われた実験です。
A.攻撃的なモデルに晒される24名、B.非攻撃的なモデルに晒される24名、C.モデルに晒されない24名、の三つのグループに大別し、さらに以下のようなグループに分け実験します。
A.
攻撃的なモデル(成人男性)の行為を観察する男児6名、女児6名
攻撃的なモデル(成人女性)の行為を観察する男児6名、女児6名
B.
非攻撃的なモデル(成人男性)の行為を観察する男児6名、女児6名
非攻撃的なモデル(成人女性)の行為を観察する男児6名、女児6名
C.
モデルに晒されない男児12名、女児12名
第一室のプレイルームで被験者となる子供たちは、同室に一緒にいるモデルとなる大人の行動を観察します。
攻撃的なモデルの大人は、ボボ人形というビニール製の空気人形を身体的および口頭で激しく攻撃します。
模倣が確認しやすいように、モデルは特徴的な攻撃および口撃をします(ハンマーで殴ったり、馬乗りになってボコったり、結構ハードです)。
非攻撃的なモデルの大人は、ボボ人形を無視して他のオモチャで普通に遊ぶだけです。
その後、ボボ人形および第一室以上に魅力的なおもちゃの沢山ある別のプレイルームに移動し、子供を遊ばせ、マジックミラー越しにその様子を記録します。
以下の表がその模倣された攻撃回数の記録の一部です。
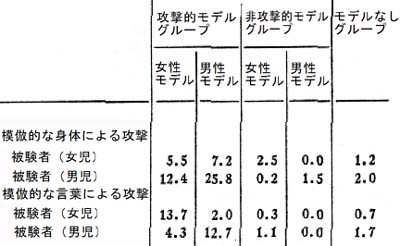
(画像元:Classics in the History of Psychology-Bandura, Ross, & Ross 1961→)
攻撃的なモデルを観察した子供たちの攻撃的模倣行動が顕著なこと、同性のモデルを模倣しやすいこと、性別によって攻撃回数に差があること、などがよく分かります。

(左-馬乗りになって攻撃する、右-木槌で攻撃する)
ボボ人形実験その2(1963)
次いで、モデルの強化が観察者の模倣反応に及ぼす影響、および学習と遂行の区別を確認する実験が行われました。
66名の児童(男児33名、女児33名)を三つのグループに分け、それぞれグループ別の映像を観せます。
前回の実験のモデルと同様、成人モデルがボボ人形に激しく攻撃する内容です。
その攻撃の映像の後、三つの別の映像をつなぎます。
一つ目の映像では、攻撃映像の後、モデルに報酬が与えられます。
別の大人が登場し、「あなたは素晴らしく強い人ですね!」というように賞賛し、ジュースや沢山のお菓子を与えます。
二つ目の映像は、攻撃映像の後、モデルに罰が与えられます。
別の大人がやってきて、そのモデルを叱りつけ、怯えたモデルはひっくり返り、その上に叱責者が馬乗りになり、叩かれたモデルは逃げ出します。
三つ目の映像は、結末がなく、ただモデルがボボ人形を攻撃する映像のみで終わります。
この三つの映像によって分けられた児童のグループは、映像を観た後、前回の実験と同様、ボボ人形やオモチャや小道具のある別室に移動し、その行動を記録されます。
その記録の後、最後に実験者が入ってきて、被験者に対し「先ほど観た映像を教えて(真似して)くれないか」と言って、その対価(動機付け)としてジュースと絵本を与えます。
以下の図がその結果です。
無誘因とは、マジックミラー越しの純粋な模倣の記録、正誘因とは、ジュースと絵本を与えた場合の模倣の記録です(下図-バンデュラ編著、原野/福島訳『モデリングの心理学』金子書房、131項)。
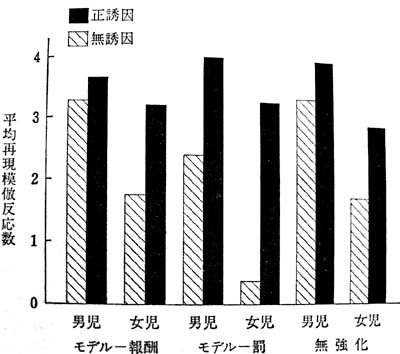
このグラフから分かることは、
1.モデルの強化要因(報酬-罰)の観察が、模倣反応の行為数に強い影響を与えること(棒グラフ-斜線)。
2.しかし、モデルの行為そのものは、どのグループも同じ程度に学習していること(棒グラフ-黒線)。
3.無報酬は強化と似たような働きをすること(前項の「脱抑制効果」)。
4.性別間に大きな差があること。
すなわち、一致反応の習得は接近によって得られるが、 モデルに与えられる強化は主に模倣学習による反応の遂行に影響を及ぼす要因である。モデルの攻撃反応が報酬を受けるのを目撃した子どもは、後になって、このモデルの行動を再現できるが、同じモデルの反応が罰せられるのを観察した子どもはその反応を再現しようとしないと言われる。実験後の面接で、後者の子どもたちの多くは、かなり正確に、モデルが行った攻撃反応の種類を述べることができた。この事実は明らかに、子どもたちが、モデルの反応に相当する認知的内容を学習しており、ただ運動という型に変換されなかったに過ぎない。この実験結果は、学習と遂行を区別することが重要であること、また強化は主に学習に関係した変数なのか、それとも遂行に関係した変数なのかを決める組織的研究が重要であることの2点を浮彫りにした。(同上、125項)
また、別のボボ人形実験では、モデルとなって攻撃するのが、1.現実の人間、2.映像内の人間、3.漫画アニメの猫キャラ、に関わらず、観察者の攻撃性は一般に比べ倍増するという結果となり、メディアの影響というものが明確になりました。
おわり